Prompt-based Gradient Projection
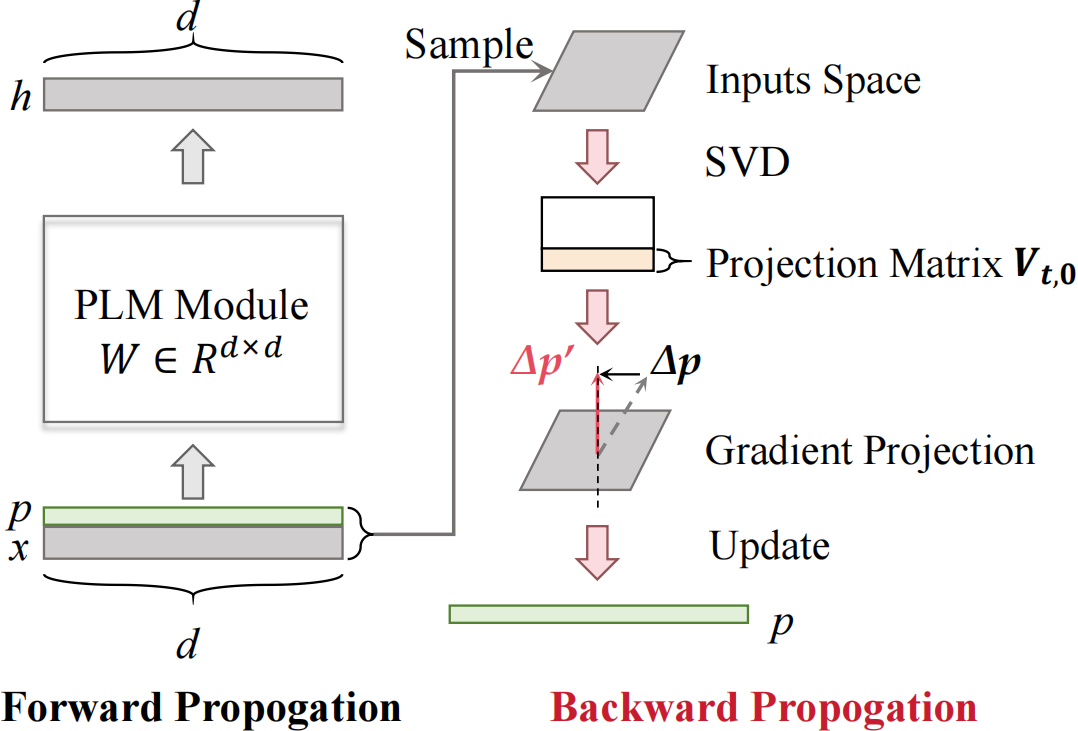
To achieve Theorem 1, i.e., the condition of anti-forgetting, the new prompts require to be:
This is a unified work about how to resist forgetting in various efficient-parameter based continual learning and the corresponding paper will release soon.
Here, we create this website to propagate our work (2024/3/3).
Our previous work 'Prompt Gradient Projection for Continual Learning' has been received by ICLR24 SpotLight!💐💐
The latest update is in 2024/5/22.
For more information, please kindly refer to our lab homepage https://dmcv-ecnu.github.io.
Catastrophic forgetting poses the primary challenge in the continual learning process of deep neural networks. Nowadays, methods based on parameter-efficient tuning (PET), which involves adding tiny extra parameters, have demonstrated impressive performance and promising perspectives in continual learning.
However, these methods are still confronted with a common problem: fine-tuning on consecutive distinct tasks can disrupt the existing parameter distribution and lead to forgetting. Recent progress mainly focused in empirically designing efficient tuning engineering, lacking investigation of forgetting generation mechanism, anti-forgetting criteria and providing theoretical support. Additionally, the unresolved trade-off between learning new content and protecting old knowledge further complicates these challenges.
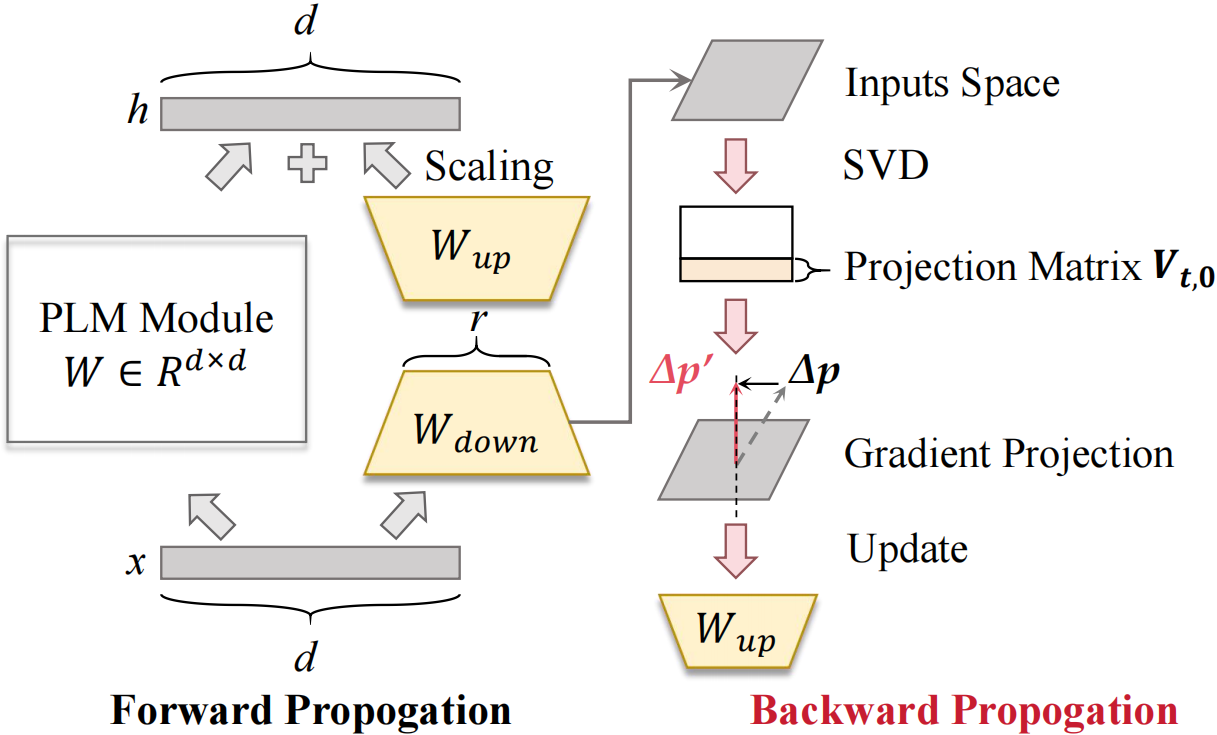
The gradient projection methodology restricts gradient updates to the orthogonal direction of the old feature space, preventing distribution of the parameters from being damaged during updating and suppressing forgetting.
Developing on it, in this paper, we reformulate Adapter, LoRA, Prefix, and Prompt to continual learning setting from the perspective of gradient projection, and propose a unified framework called Parameter Efficient Gradient Projection (PEGP), Based on the condition that old tasks should have the same results after model updated, we introduce orthogonal gradient projection into different PET paradigms and theoretically demonstrate that the orthogonal condition for the gradient can effectively resist forgetting in PET-based continual methods. Notably, PEGP is the first unified method to provide an anti-forgetting mechanism with mathematical demonstration for different tuning paradigms.
Additionally, through experiments on a novel cross-modality dataset BITM, we further discover that PEGP can not only alleviate forgetting but also suppress the appearance of hallucination during continual learning process, which provide a new insight for addressing hallucination in the cross-modality continual learning. Additionally, by conducting Singular Value Decomposition (SVD) to obtain gradient projection matrix, PEGP is proved as the optimal solution to balance the trade-off between plasticity and stability in PET continual learning methods.
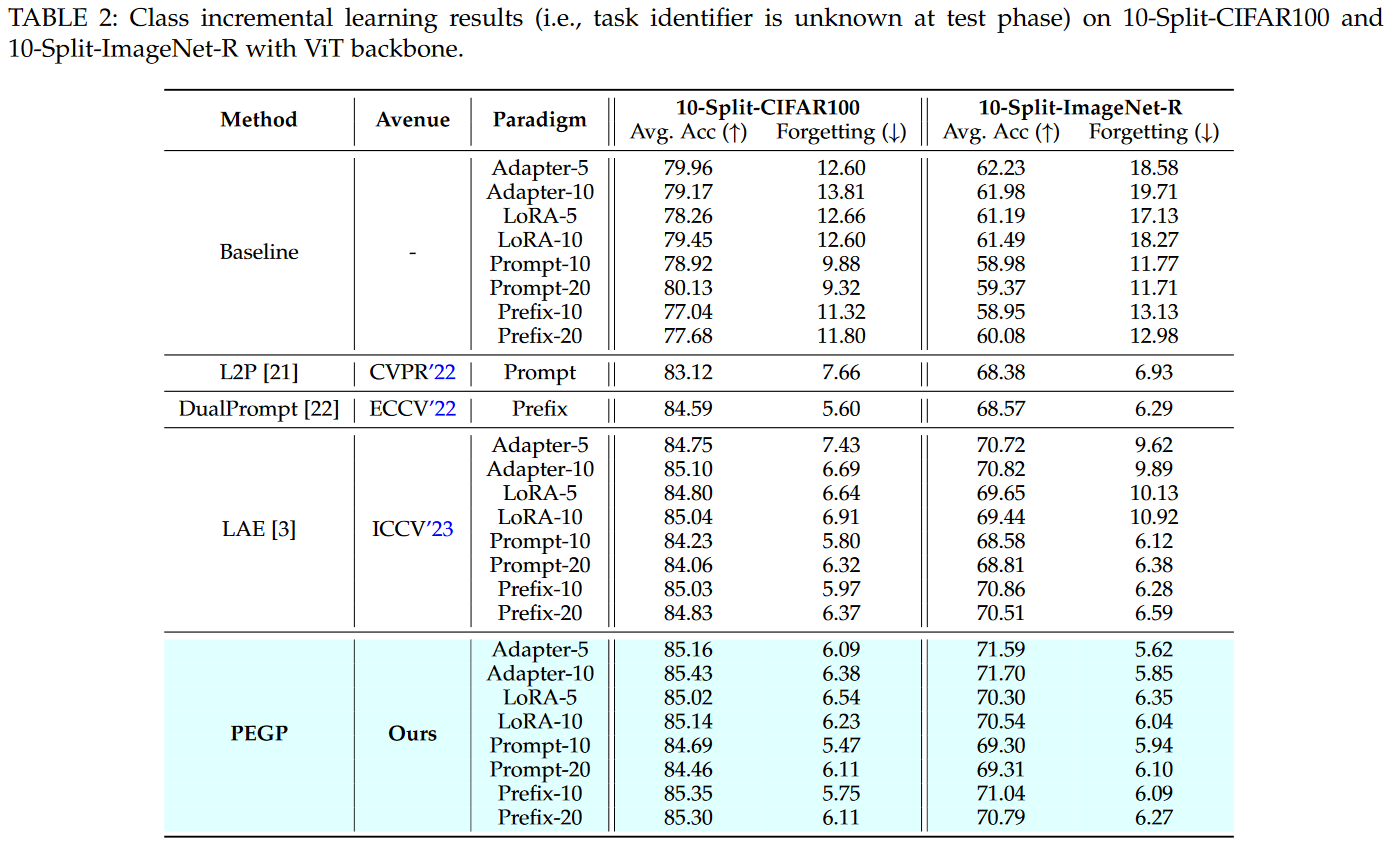
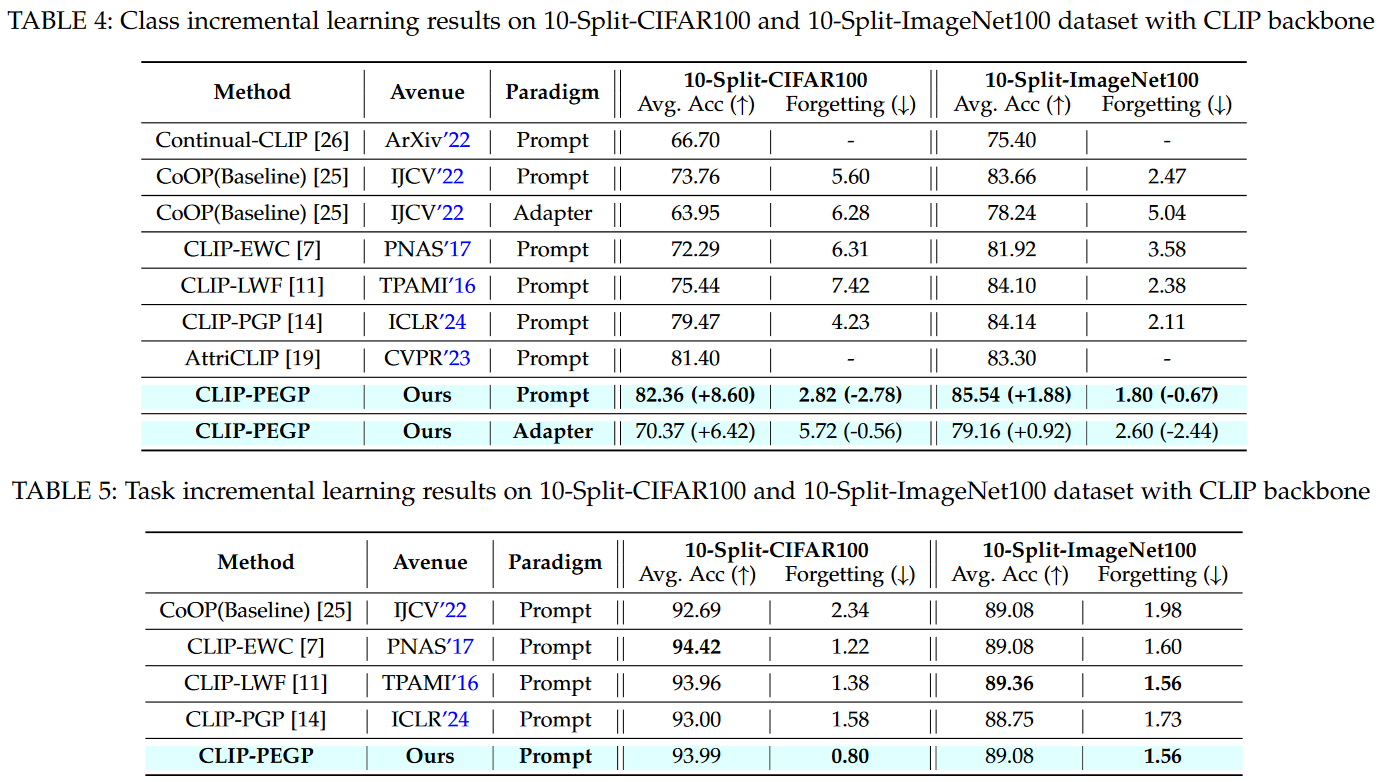
We extensively evaluate our method with different backbones on diverse datasets, and experiments demonstrate its efficiency in reducing forgetting in class incremental, online class incremental, domain incremental, task incremental, and multi-modality incremental settings.
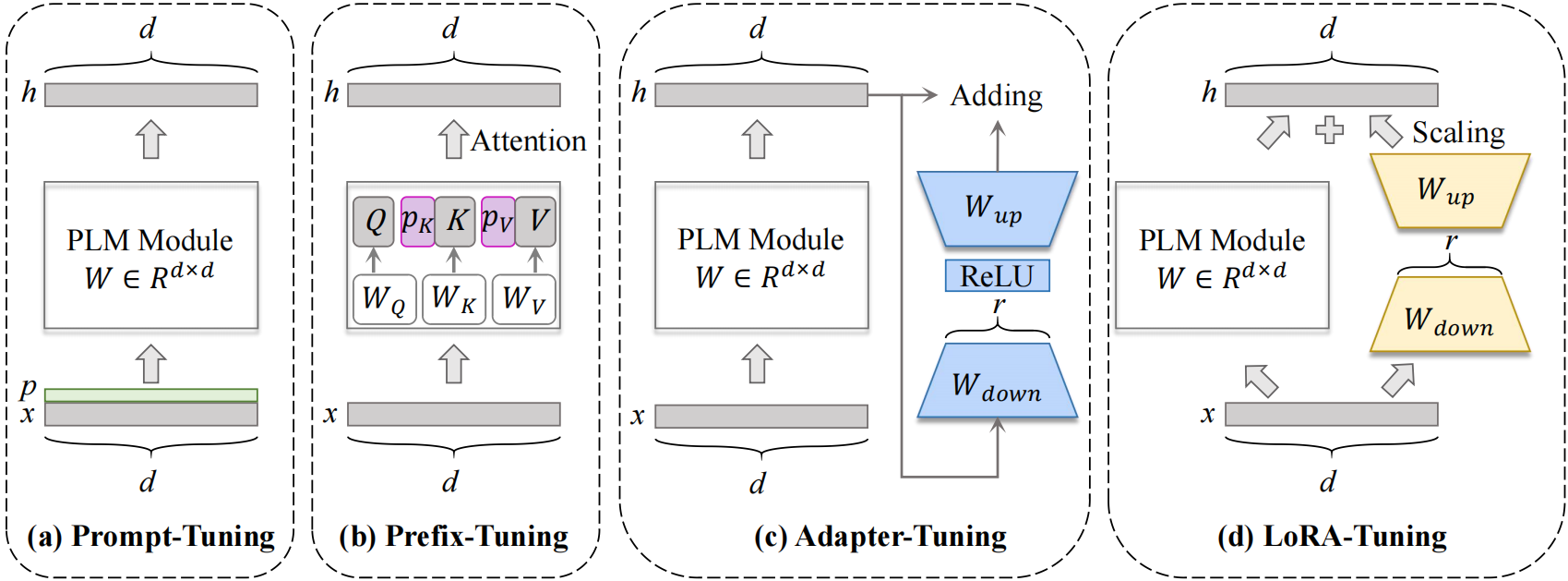
Visualization of distinct parameter-efficient tuning paradigms
For various parameter efficient tuning paradigms, to better preserve old knowledge, we propose that the update of network would satisfy the following theorems.
Prompt-Tuning:
Theorem 1.
Prefix-Tuning:
Theorem 2.
where
Adapter-Tuning:
Theorem 3.
LoRA-Tuning:
Theorem 4.
To achieve Theorem 1, i.e., the condition of anti-forgetting, the new prompts require to be:
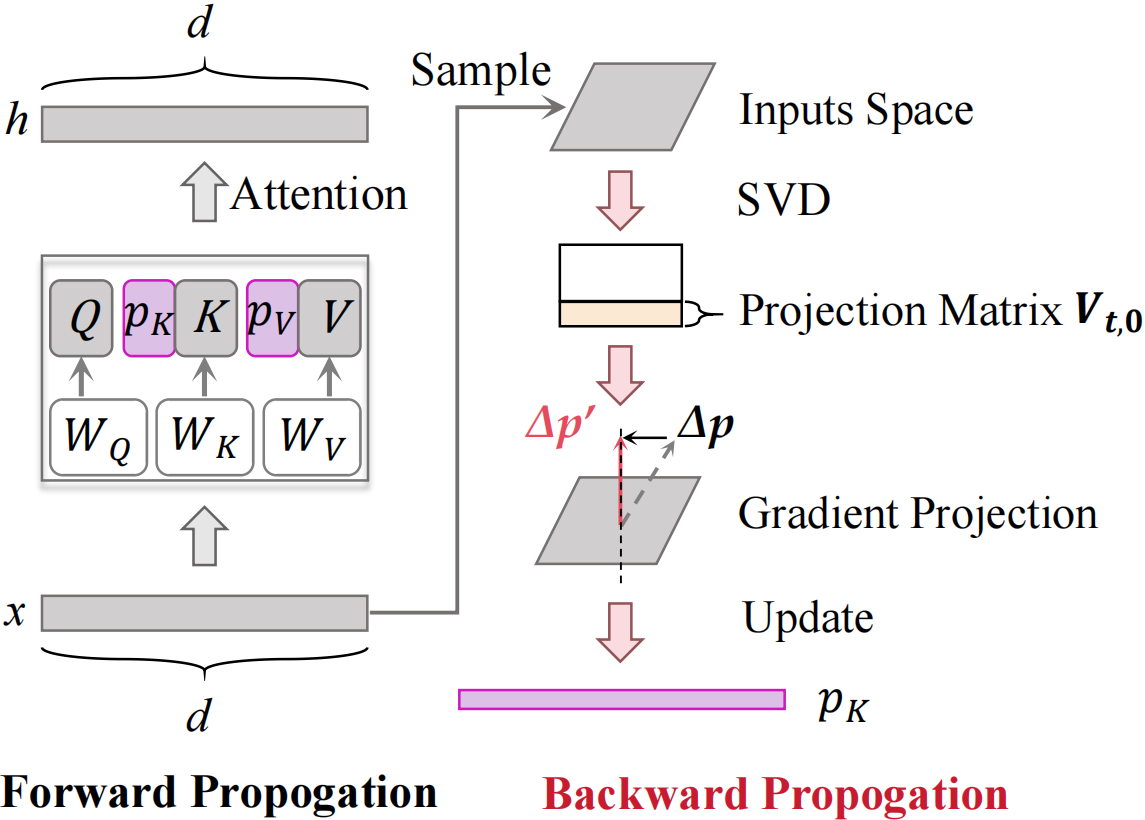
To achieve Theorem 2, i.e., the condition of anti-forgetting, the new prompts require to be:
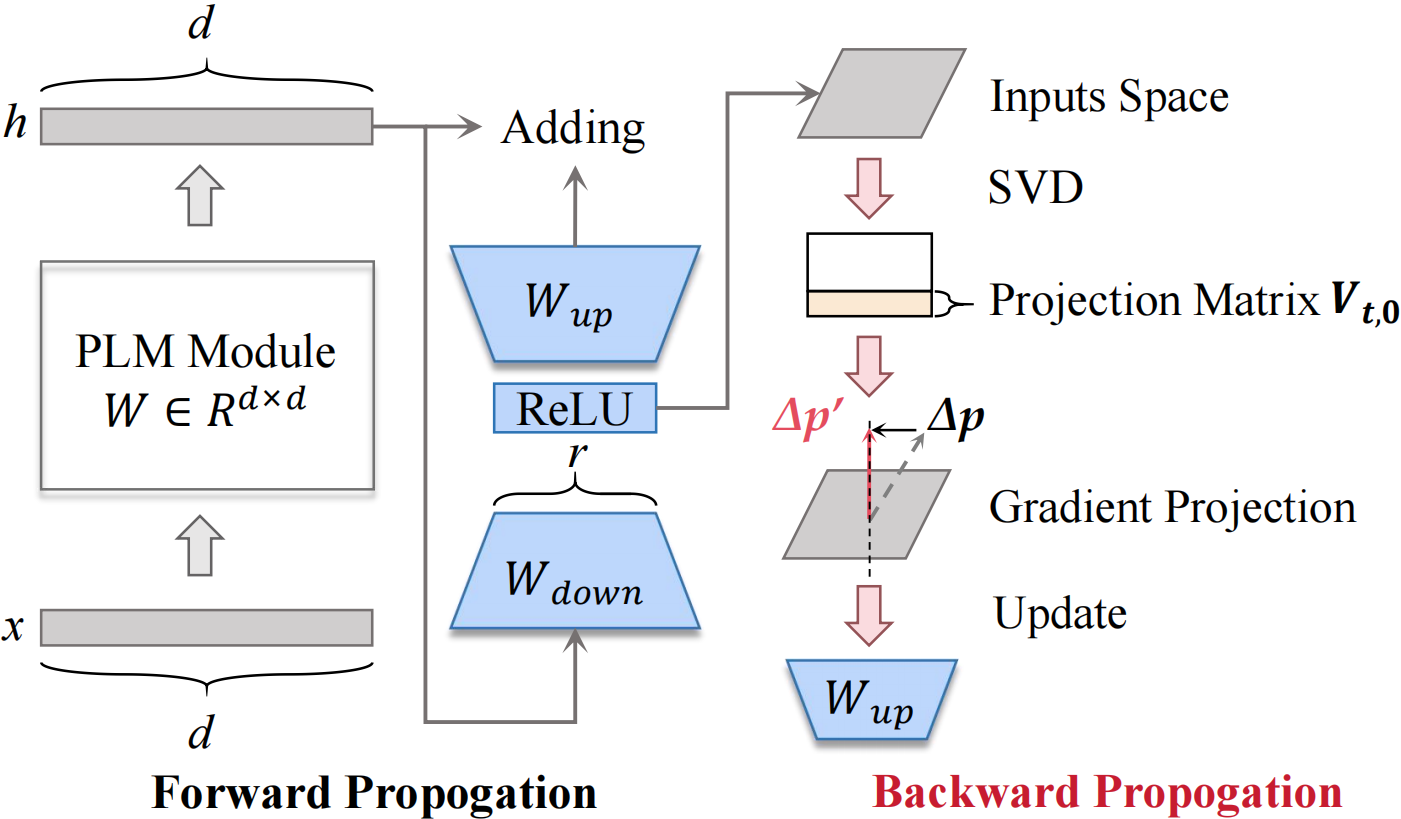
To achieve Theorem 3, i.e., the condition of anti-forgetting, the new prompts require to be:
To achieve Theorem 4, i.e., the condition of anti-forgetting, the new prompts require to be:


T-SNE results of prompt and prompt-pg on 10-Split-CIFAR100 dataset with ViT backbone. The left column represents prompt, and the right column represents prompt-gp. The red circle means the drawback existing in prompt, and the blue circle shows the improvement of our method.
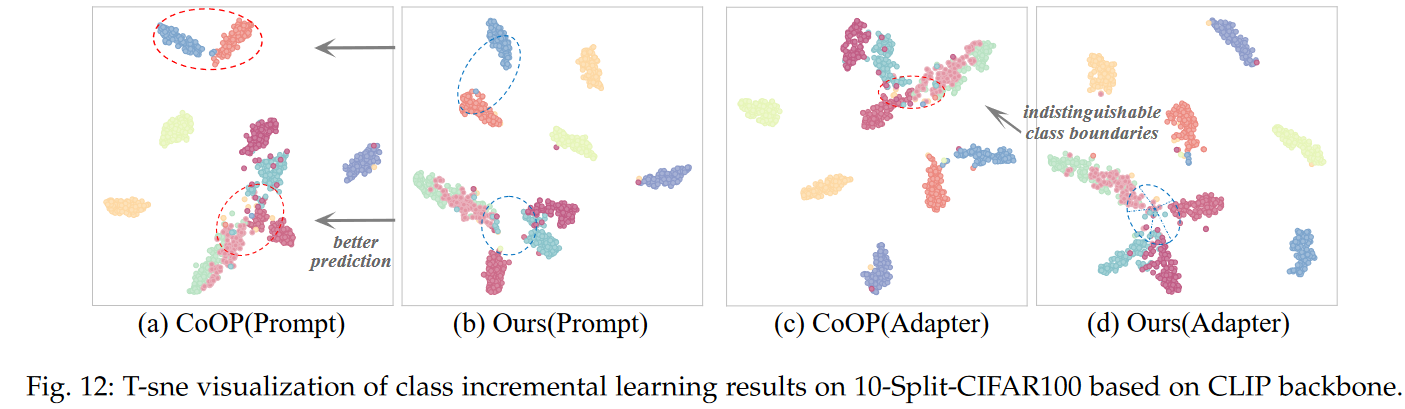
T-SNE results of prompt and linear adapter on 10-Split-CIFAR100 dataset with CLIP backbone.

OnlineClass incremental learning results of prefix/prompt tuning paradigms with ViT backbone.
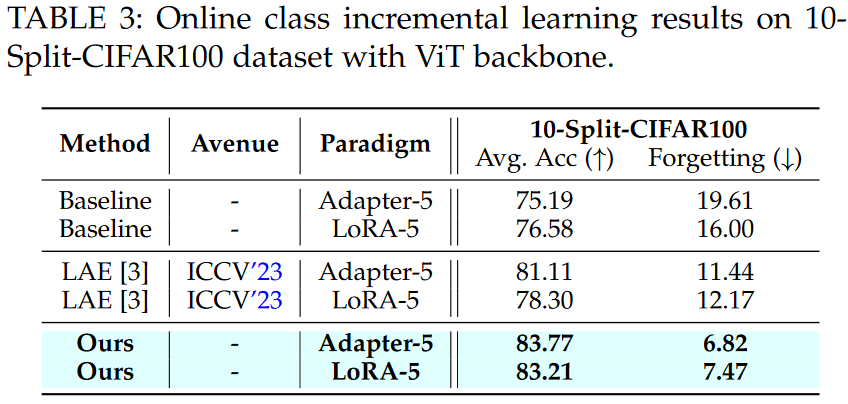
OnlineClass incremental learning results of adapter/lora tuning paradigms with ViT backbone.
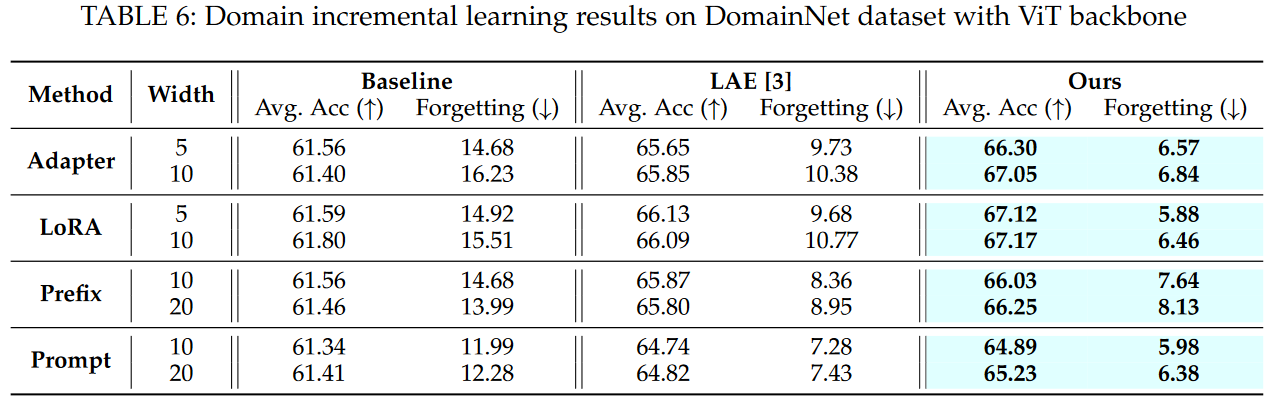
Domain incremental learning results of prefix/prompt/adapter/lora tuning paradigms with ViT backbone.
@article{qiao2024gradient,
title={Gradient Projection For Parameter-Efficient Continual Learning},
author={Qiao, Jingyang and Zhang, Zhizhong and Tan, Xin and Qu, Yanyun and Zhang, Wensheng and Xie, Yuan},
journal={arXiv preprint arXiv:2405.13383},
year={2024}
}